最近Google連續辦了兩次ML Study Jam的活動,包含
ML Study Jam 機器學習培訓計劃- 初級- 首頁,以及ML Study Jam 機器學習培訓計劃- 進階-首頁,這兩階段的課程內容,個人覺得非常適合企業在導入ML給同仁必上的內容,尤其適合非科班出身的又想轉型的朋友們。
在進階課程的當中,筆者覺得在「How Google does Machine Learning」當中,有許多有趣的題目與內容,是自己多年做資料科學服務有所共鳴的,希望能夠透過部落格分享學習的心得,提供給想導入ML的企業與想持續學習導入ML的朋友。(請注意本篇文章僅針對部分題目提供心得分享,並非答案分享)
過去筆者在導入多年的資料科學服務當中,發現資料科學家要有一個非常重要的能力,是能夠快速辨識這家企業與題目,到哪一個階段,接著再給予對應的服務內容,避免導入過程資源的浪費,而課程當中Google整理了一個「Path to ML」來幫忙大家釐清企業的ML導入階段。
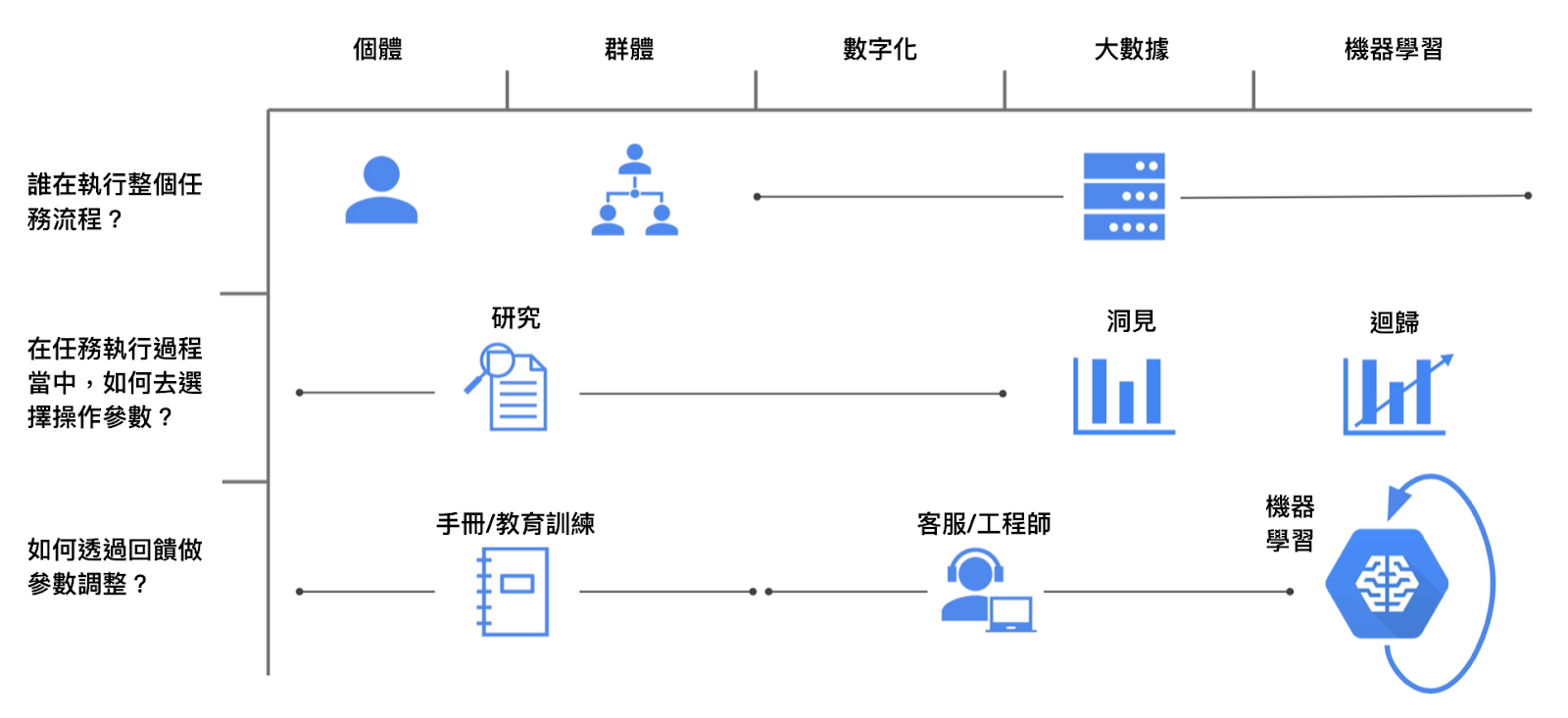
在Module 3 Quiz的部分,有一題要學員能夠針對題目,以「Path to ML」五階段做辨認,而其中五階段包含「Individual contributor」、「Delegation」、「Digitization」、「Big data and Analytics」、「Machine learning」,在ML and Business Processes課程當中,個人覺得非常好的一個觀念是,企業要導入一個從無ML->有ML的過程,必須先找到流程上的輸入與輸出,接著在輸出中透過數據與ML找出具有洞見的結果,將結果回到流程上去改善輸出。
因此回到「Path to ML」,我們首先要能夠辨認,我們在企業流程中,到底是哪一個階段,才能去藉由階段工作來正確導入ML,筆者整理如下:
I for individual contributor:任務的本體,如單一櫃員
D for delegation:多個可執行任務的人,如多個店員
Z for digitization:數位化的工具,如ATM,可以透過機器進行重複化的工作
B for big data and analytics:透過資料挖掘洞見,提升營運效率,如汽車生產
M for machine learning:透過前面的數據,以機器學習來自動化改善整個營運效益,如推薦系統
聰明的朋友,如果題目如下,您會將上述的I,D,Z,B,M,分別放在哪裡呢?
問題1
製造工廠有許多機械手臂,整個生產團隊透過手臂上收集的數據來幫助確定生產的時間表。
問題2
一個客戶服務團隊持續接收在線上的訂單
問題3
一個圖書館員在城市圖書館工作
問題4
停車收費系統根據可能預期的需求來自動改變費率
問題5
自動電子收費器透過讀取汽車牌照跟駕駛索取過路費(如ETC)
問題1看起來非常明顯是以數據來挖掘洞見,問題2與問題3很容易理解是傳統的運作階段,問題4與問題5比較容易會有誤會是在「digitization」與「machine learning」的差別,但仔細一看,事實上ML有個關鍵是透過數據「自動化」原先的流程,因此會獲得一個不斷改變的輸出,答案就出來了。
看起來大家都有十足的把握了,我們繼續看一下去,如果題目如下,您們的選擇為何?
題目6
所有任務,包含執行參數、選擇參數、參數回饋都是自動化
題目7
一個人在執行任務,而這個任務與指令來自人與人之間的方式運作
題目8
一個電腦執行任務,而軟體工程師透過歷史的模式,來進行參數的調整。
題目9
一個電腦執行過程是透個人從介面上輸入參數來進行。
題目10
一個任務是從一群人來完成
問題6我們可以發現全數自動化,會是機器學習的強項,答案是非常明確的。接著在問題7與問題10的部分,也很容易辨識是傳統1個與多個人的運作方式,最後這次的題目8與題目9分別就相對明顯很多,題目9單純只有透過介面來做互動,而題目8則透過數據挖掘模式來進行參數調整。
最後在Quiz最尾端的題目也非常有趣,題目大意是在說一家企業需要在一年內導入ML,我們是這家企業的顧問,而我們應該請該企業集中資源在哪一個地方,譬如說:「定義關鍵目標」、「收集資料」、「建立基礎設施」、「最佳化演算法」、「整合模型」。
其實有經驗的顧問會選擇「收集資料」,因為這是所有企業導入ML的最重要的問題,尤其以筆者過去的經驗是,傳統企業常常是因為沒有資料而無法導入ML。而其他都不重要嗎?並不是,而是沒有資料,對於定好目標、建立設施、最佳化算法、整合模型就都沒有了意義。
但是筆者提一個觀點是,如果我們企業要導入ML,也不能盲目的收集資料,而是要了解解決什麼問題。
所以回過頭來,一樣可以觀察公司目前的階段,從沒有ML->有ML,我們在「Individual contributor」、「Delegation」、「Digitization」、「Big data and Analytics」、「Machine learning」是哪一個階段,才能將資源妥善運用在導入ML的正確方向當中。
以上是筆者對於「How Google does Machine Learning」的Module 3 Quiz拙見,歡迎討論。