

大家好我是Jerry老師,週一要上班了,趕快來把上週在Google I/O Connect 2024 的經驗做個分享,疫情後連續兩年參加Google I/O 的活動,之前在上海,今年在北京。晚上的晚宴很有趣,這次有東南亞的社群朋友,很熱鬧,中、英交叉主持。

大中華的主管們分享

有趣的問題,大家猜到了嗎

全球生態圈的大老闆分享
今年辦在北京國家會議中心(China National Convention Center)


入口報到

從另一個角度拍攝,大家魚貫上手扶梯

一樣看起來很酷炫的Keynote開場,滿滿的人

一如往常Google介紹貢獻,有個編譯夢想的計畫,很特別



GenAI的個人化應用種類

完整的生態圈

Chrome也有 AI計畫
基本上 Google生態圈的產品,都已經開始支援Gemini做各種不同的應用
相當期待

Google的公益也做了不少

聽障的公益



可以提足球,透過AI評分





VertexAI開發的環境




支援幾個常見的LLM模型

這個真的滿重要的,因為現在LLM可以讀超過我們人類讀的速度

在Web上做推論
中間還有特色禮品跟飲品




這個概念很不錯,看起來就是透過Google技術把最後一哩路走完

PaliGemma是一個可以做圖文的雙模態

這的確是Google的夢想,也是Jerry老師的夢想,只有這樣這個世界才會透過科技更強大




透過生成式AI評分,相當有趣的應用,因為Gemini已經可以多模態,
所以他透過影片來進行分析。

透過這張圖來解釋 嵌入的關係

在Firebase上的應用









接下來是Jerry老師覺得最棒的一個收穫,是關於RAG應用,
當然活動中有不少介紹RAG的場次,但這場介紹的最好

何謂RAG

RAG範例

RAG的優勢

RAG搜尋

文字與圖片進行Chunking

多模態的混合
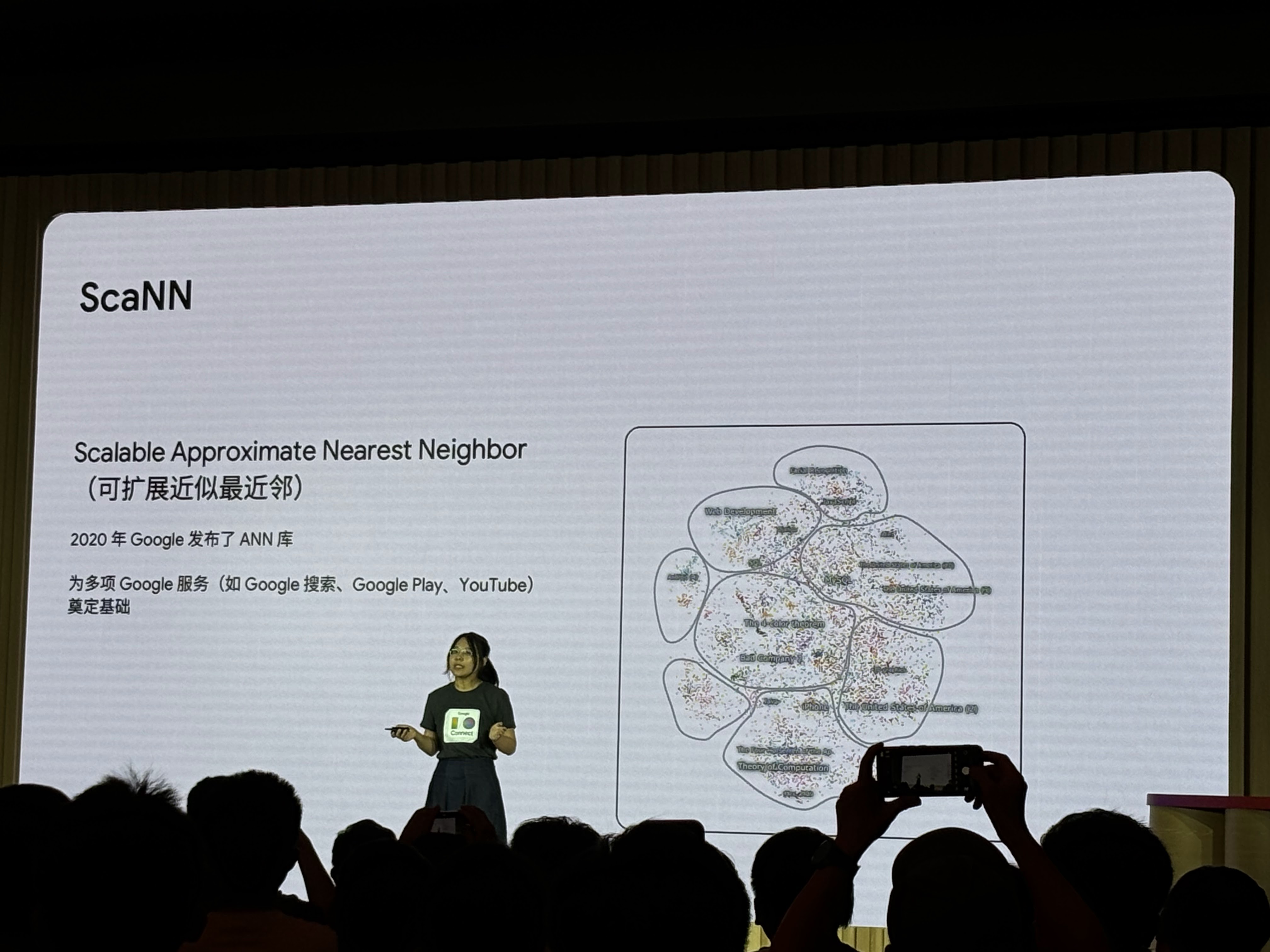
Google採用到目前為止最好的維度搜尋技術ScaNN

在Google Cloud上的引擎

混合搜尋,這塊也是近年大家的新作法

客製化RAG應用

智能分塊的概念也值得參考

的確是能強化RAG的做法之一

這個做法在開源也有類似的參考

捕捉真實答案的方法

接地氣的範例

這是 Uber的案例,比較像是搜尋+對話生成的方式

Uber的架構範例

Uber的架構範例

用多模態來讀論文(這種也是跟過去只讀文字是不同的)

範例流程

範例都在這裡
總結一下這次的心得,Google短短不到一年,
將所有產品圍繞Gemini + RAG,很期待接下來在整個生態的應用展開。
歡迎寫信給 jerry@ap-mic.com交流